
دستورات صوتی فقط برای دستیارانی مانند Google یا Alexa نیست. آنها همچنین می توانند به برنامه های تلفن همراه و دسک تاپ شما اضافه شوند ، هم قابلیت های اضافی و حتی سرگرم کننده را برای کاربران نهایی شما ارائه می دهند. و افزودن دستورات صوتی یا جستجوی صوتی به برنامه های شما بسیار آسان است. در این مقاله ، ما از Web Speech API برای ساخت یک برنامه جستجوی صوتی کنترل کتاب استفاده خواهیم کرد.
کد کامل آنچه را که خواهیم ساخت در آن موجود است GitHub. و برای افراد بی تاب ، یک نسخه نمایشی فعال از آنچه در انتهای مقاله خواهیم ساخت وجود دارد.
مقدمه ای بر API گفتار وب
قبل از شروع ، توجه به این نکته مهم است که API گفتار وب در حال حاضر محدود است پشتیبانی از مرورگر. برای پیگیری این مقاله ، شما نیاز دارید از یک مرورگر پشتیبانی شده استفاده کنید.
داده های مربوط به پشتیبانی از ویژگی mdn-api__SpeechRecognition در مرورگرهای اصلی
اول ، بیایید ببینیم که دستیابی به آن آسان است Web Speech API بالا و در حال اجرا (همچنین ممکن است بخواهید مقدمه SitePoint در API گفتار وب را بخوانید و برخی از آزمایشات دیگر با Web Speech API را بررسی کنید.) برای شروع استفاده از Speech API ، ما فقط باید یک نمونه جدید ارائه دهیم. SpeechRecognition کلاس برای اجازه دادن به ما به گوش دادن به صدای کاربر:
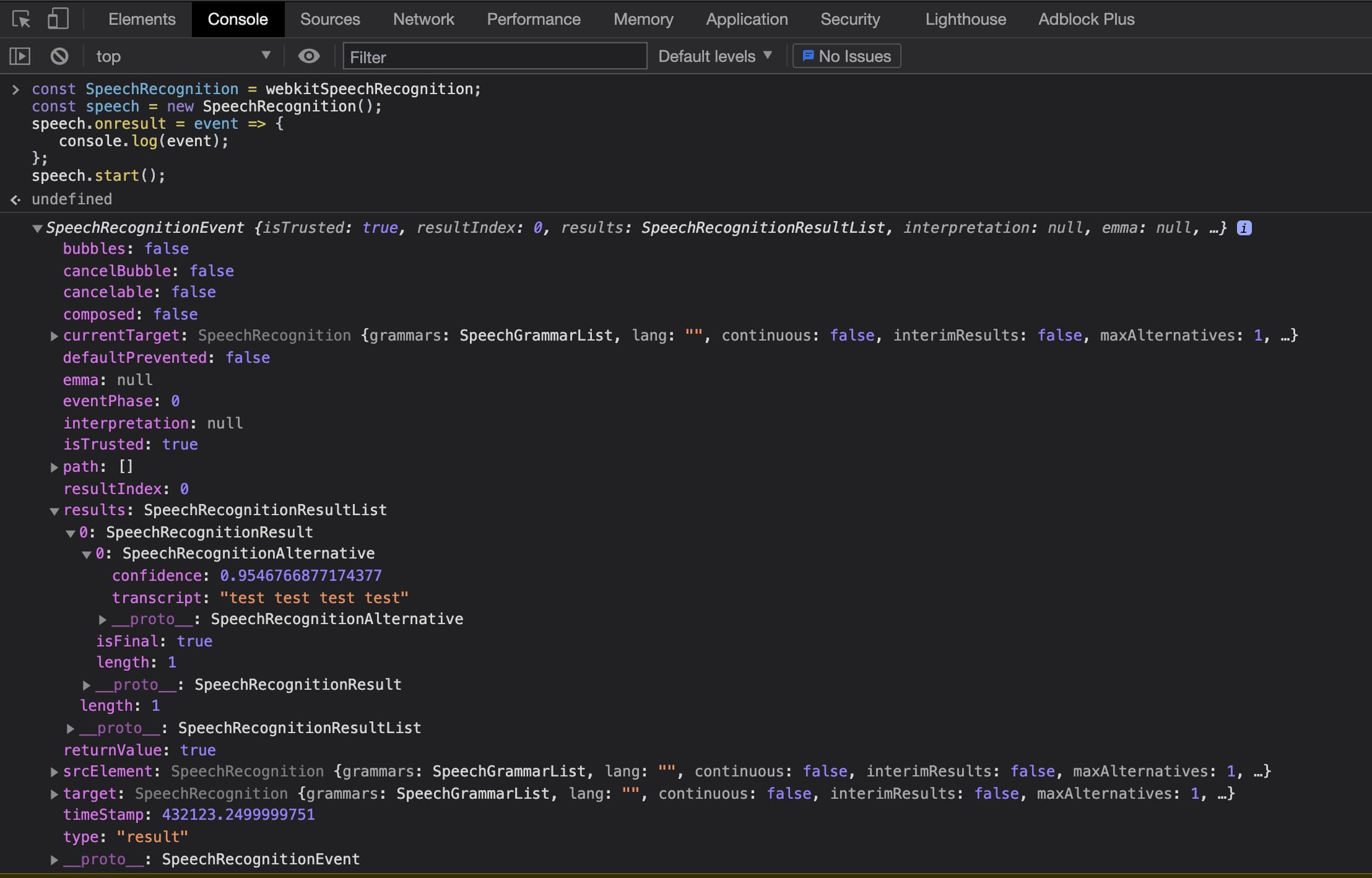
const SpeechRecognition = webkitSpeechRecognition;
const speech = new SpeechRecognition();
speech.onresult = event => {
console.log(event);
};
speech.start();ما با ایجاد یک شروع می کنیم SpeechRecognition ثابت ، که برابر با پیشوند فروشنده جهانی مرورگر است webkitSpeechRecognition. پس از این ، می توانیم یک متغیر گفتاری ایجاد کنیم که نمونه جدید ما باشد SpeechRecognition کلاس این به ما امکان می دهد گوش دادن به صحبت های کاربر را شروع کنیم. برای اینکه بتوانیم نتایج را از طریق صدای کاربر کنترل کنیم ، باید یک شنونده رویداد ایجاد کنیم که با قطع کردن صحبت کاربر فعال شود. در آخر ، ما start عملکرد در نمونه کلاس ما.
هنگام اجرای این کد برای اولین بار ، از کاربر خواسته می شود که به میکروفون دسترسی داشته باشد. این یک بررسی امنیتی است که مرورگر برای جلوگیری از جاسوسی ناخواسته انجام می دهد. پس از اینکه کاربر پذیرفت ، می تواند صحبت را شروع کند ، و دیگر از آن دامنه اجازه نمی گیرد. پس از قطع صحبت کاربر ، onresult عملکرد کنترل کننده رویداد فعال خواهد شد.
onresult رویداد منتقل می شود SpeechRecognitionEvent شی ، که از a تشکیل شده است SpeechRecognitionResultList آرایه نتایج SpeechRecognitionResultList شی شامل SpeechRecognitionResult اشیاء. اولین مورد در آرایه a را برمی گرداند SpeechRecognitionResult شی ، که شامل یک آرایه دیگر است. اولین مورد در این آرایه شامل متن آنچه کاربر گفته است.
کد فوق را می توان از Chrome DevTools یا یک پرونده جاوا اسکریپت معمولی اجرا کرد. اکنون که اصول آن را فهمیدیم ، بیایید نگاهی به ساخت این برنامه در یک React بیندازیم. هنگام اجرای از طریق کنسول Chrome DevTools می توانیم نتایج زیر را مشاهده کنیم.
استفاده از گفتار وب در React
با استفاده از آنچه قبلاً آموخته ایم ، افزودن Web Speech API به برنامه React یک فرایند ساده است. تنها مسئله ای که باید با آن روبرو شویم چرخه عمر م componentلفه React است. اول ، بیایید یک پروژه جدید با ایجاد کنیم برنامه React ایجاد کنید، راهنمای شروع آن را دنبال کنید. این فرض می کند که گره بر روی دستگاه شما نصب شده است:
npx create-react-app book-voice-search
cd book-voice-search
npm startبعد ، ما جایگزین می کنیم App برای تعریف یک جز basic اصلی React ، با کد زیر فایل کنید. سپس می توانیم منطق گفتاری را به آن اضافه کنیم:
import React from 'react';
const App = () => {
return (
<div>
Example component
</div>
);
};
export default App;این م componentلفه ساده یک div را با مقداری متن در داخل آن ارائه می دهد. اکنون می توانیم منطق گفتار خود را به م componentلفه اضافه کنیم. ما می خواهیم مولفه ای ایجاد کنیم که نمونه گفتار را ایجاد کند ، سپس از آن در چرخه حیات React استفاده کنید. وقتی م componentلفه React برای اولین بار ارائه می شود ، ما می خواهیم نمونه گفتار را ایجاد کنیم ، شروع به گوش دادن به نتایج کنیم و راهی برای شروع تشخیص گفتار در اختیار کاربر قرار دهیم. ابتدا باید برخی از قلاب های React را وارد کنیم (می توانید در اینجا درباره قلاب های اصلی React اطلاعات بیشتری کسب کنید) ، برخی از CSS سبک ها، و تصویر میکروفن برای کلیک کاربر ما:
import { useState, useEffect } from "react";
import "./index.css";
import Mic from "./microphone-black-shape.svg";پس از این ، ما نمونه گفتار خود را ایجاد خواهیم کرد. ما می توانیم هنگام مشاهده اصول API گفتار وب ، از آنچه قبلاً آموخته ایم ، استفاده کنیم. ما باید در کد اصلی که در ابزارهای توسعه دهنده مرورگر جایگذاری کردیم ، چند تغییر ایجاد کنیم. در مرحله اول ، ما با افزودن تشخیص پشتیبانی مرورگر ، کد را قوی تر می کنیم. ما می توانیم این کار را با بررسی اینکه آیا انجام می شود انجام دهیم webkitSpeechRecognition کلاس روی شی window پنجره وجود دارد. اگر مرورگر از API مورد نظر ما استفاده کند ، به ما اطلاع می دهد.
سپس ما تغییر continuous تنظیم به درست است. با این کار API تشخیص گفتار برای مداوم گوش دادن پیکربندی می شود. در اولین مثال ما ، این به طور پیش فرض نادرست بود و به این معنی بود که وقتی کاربر صحبت خود را متوقف کرد ، onresult کنترل کننده رویداد باعث می شود. اما همانطور که به کاربر اجازه می دهیم چه زمانی بخواهد سایت گوش دادن را متوقف کند ، ما از آن استفاده می کنیم continuous به کاربر اجازه می دهد تا زمانی که می خواهد صحبت کند:
let speech;
if (window.webkitSpeechRecognition) {
const SpeechRecognition = webkitSpeechRecognition;
speech = new SpeechRecognition();
speech.continuous = true;
} else {
speech = null;
}
const App = () => { ... };اکنون که کد شناسایی گفتار را تنظیم کردیم ، می توانیم از این کار در داخل م componentلفه React استفاده کنیم. همانطور که قبلاً دیدیم ، ما دو قلاب React وارد کردیم – useState و useEffect قلاب اینها به ما اجازه می دهد onresult شنونده رویداد و متن کاربر را برای بیان ذخیره کنید تا بتوانیم آن را در UI نمایش دهیم:
const App = () => {
const [isListening, setIsListening] = useState(false);
const
= useState("");
const listen = () => {
setIsListening(!isListening);
if (isListening) {
speech.stop();
} else {
speech.start();
}
};
useEffect(() => {
if (!speech) {
return;
}
speech.onresult = event => {
setText(event.results[event.results.length - 1][0].transcript);
};
}, []);
return (
<>
<div className="app">
<h2>Book Voice Search</h2>
<h3>Click the Mic and say an author's name</h3>
<div>
<img
className={`microphone ${isListening && "isListening"}`}
src={Mic}
alt="microphone"
onClick={listen}
/>
</div>
<p>{text}</p>
</div>
</>
);
}
export default App;در جز component خود ، ما ابتدا دو متغیر حالت را اعلام می کنیم – یکی برای نگه داشتن متن متن از گفتار کاربر ، و دیگری برای تعیین اینکه آیا برنامه ما به کاربر گوش می دهد. ما React می نامیم useState قلاب ، عبور مقدار پیش فرض از false برای isListening و یک رشته خالی برای متن. این مقادیر براساس تعاملات کاربر بعداً در م onلفه به روز می شوند.
بعد از اینکه حالت خود را تنظیم کردیم ، تابعی ایجاد می کنیم که با کلیک کاربر بر روی تصویر میکروفون ، عملکرد آن شروع می شود. این بررسی می کند که آیا برنامه در حال گوش دادن است. اگر اینگونه باشد ، تشخیص گفتار را متوقف می کنیم. در غیر این صورت ، ما آن را شروع می کنیم. بعداً این عملکرد به onclick برای تصویر میکروفون
سپس ما باید شنونده رویداد خود را اضافه کنیم تا از کاربر نتیجه بگیریم. ما فقط باید یک بار این شنونده رویداد را ایجاد کنیم ، و فقط زمانی که UI ارائه شده باشد به آن نیاز داریم. بنابراین می توانیم از a استفاده کنیم useEffect قلاب برای ضبط هنگامی که م theلفه سوار شده است و ایجاد ما onresult رویداد. ما همچنین یک آرایه خالی را به useEffect عملکرد به طوری که فقط یک بار اجرا می شود.
سرانجام ، ما می توانیم عناصر رابط کاربر مورد نیاز را برای اجازه دادن به کاربر برای شروع صحبت و دیدن نتایج متن ارائه دهیم.
قلاب صوتی React قابل استفاده مجدد
اکنون ما یک برنامه کاربردی React داریم که می تواند به صدای کاربر گوش دهد و آن متن را روی صفحه نمایش دهد. با این حال ، ما می توانیم این کار را با ایجاد React hook اختصاصی خود انجام دهیم که بتوانیم برای گوش دادن به ورودی های صوتی کاربران ، از آن در سراسر برنامه ها استفاده مجدد کنیم.
ابتدا ، بیایید یک فایل جاوا اسکریپت جدید به نام ایجاد کنیم useVoice.js. برای هر قلاب React سفارشی ، بهتر است از الگوی نام فایل پیروی کنید useHookName.js. این باعث می شود هنگام مشاهده پرونده های پروژه برجسته شوند. سپس می توانیم تمام قلاب های React داخلی را که قبلاً در م componentلفه مثال خود استفاده کرده ایم وارد کنیم:
import { useState, useEffect } from 'react';
let speech;
if (window.webkitSpeechRecognition) {
const SpeechRecognition = SpeechRecognition || webkitSpeechRecognition;
speech = new SpeechRecognition();
speech.continuous = true;
} else {
speech = null;
}این همان کدی است که ما قبلاً در م componentلفه React خود استفاده کردیم. بعد از این ، ما تابع جدیدی را به نام اعلام می کنیم useVoice. ما با نام پرونده مطابقت داریم که این نیز در قلاب های React سفارشی معمول است:
const useVoice = () => {
const
= useState('');
const [isListening, setIsListening] = useState(false);
const listen = () => {
setIsListening(!isListening);
if (isListening) {
speech.stop();
} else {
speech.start();
}
};
useEffect(() => {
if (!speech) {
return;
}
speech.onresult = event => {
setText(event.results[event.results.length - 1][0].transcript);
setIsListening(false);
speech.stop();
};
}, [])
return {
text,
isListening,
listen,
voiceSupported: speech !== null
};
}
export {
useVoice,
};درون useVoice عملکرد ، ما چندین کار را انجام می دهیم. مشابه نمونه م componentلفه ما ، ما دو مورد حالت ایجاد می کنیم – isListening پرچم ، و متن متن. سپس ما ایجاد می کنیم listen دوباره با همان منطق قبلی استفاده کنید ، با استفاده از یک قلاب افکت برای تنظیم onresult شنونده رویداد
در آخر ، ما یک شی object را از تابع برمی گردانیم. این شی allows به قلاب سفارشی ما اجازه می دهد تا هر م componentلفه ای را با استفاده از صدای کاربر به عنوان متن ارائه دهد. ما همچنین متغیری را بازمی گردانیم که می تواند در صورت پشتیبانی مرورگر از Web Speech API ، که بعداً از آن در برنامه خارج استفاده خواهیم کرد ، به مولفه مصرف کننده اطلاع دهد. در انتهای پرونده ، عملکرد را صادر می کنیم تا بتوان از آن استفاده کرد.
بیایید اکنون به حال خود برگردیم App.js پرونده را شروع کرده و از قلاب سفارشی ما استفاده کنید. ما می توانیم با حذف موارد زیر شروع کنیم:
SpeechRecognitionنمونه های کلاس- واردات برای
useState - متغیرهای حالت برای
isListeningوtext -
listenتابع -
useEffectبرای اضافه کردنonresultشنونده رویداد
سپس می توانیم سفارشی خود را وارد کنیم useVoice واکنش قلاب:
import { useVoice } from './useVoice';ما مانند یک قلاب React داخلی شروع به استفاده از آن می کنیم. ما تماس می گیریم useVoice عملکرد و تجزیه شی object حاصل:
const {
text,
isListening,
listen,
voiceSupported,
} = useVoice();پس از وارد کردن این قلاب سفارشی ، ما نیازی به تغییر در م theلفه نداریم زیرا از همه نام متغیرهای حالت و تماس های عملکردی استفاده مجدد کردیم. App.js حاصل باید به صورت زیر باشد:
import React from 'react';
import { useVoice } from './useVoice';
import Mic from './microphone-black-shape.svg';
const App = () => {
const {
text,
isListening,
listen,
voiceSupported,
} = useVoice();
if (!voiceSupported) {
return (
<div className="app">
<h1>
Voice recognition is not supported by your browser, please retry with a supported browser e.g. Chrome
</h1>
</div>
);
}
return (
<>
<div className="app">
<h2>Book Voice Search</h2>
<h3>Click the Mic and say an author's name</h3>
<div>
<img
className={`microphone ${isListening && "isListening"}`}
src={Mic}
alt="microphone"
onClick={listen}
/>
</div>
<p>{text}</p>
</div>
</>
);
}
export default App;ما اکنون برنامه خود را به گونه ای ساخته ایم که به ما امکان می دهد منطق Web Speech API را در بین اجزا یا برنامه ها به اشتراک بگذاریم. همچنین می توانیم تشخیص دهیم که آیا مرورگر از Web Speech API پشتیبانی می کند یا خیر و به جای یک برنامه خراب ، پیامی را بازگردانیم.
این همچنین منطق را از م componentلفه ما پاک می کند ، و آن را تمیز و حفظ می کند. اما اجازه دهید در اینجا متوقف نشویم. بیایید قابلیت های بیشتری به برنامه خود اضافه کنیم ، زیرا در حال حاضر فقط به صدای کاربر گوش می دهیم و آن را نمایش می دهیم.
جستجوی صوتی کتاب
با استفاده از آنچه تاکنون آموخته ایم و ساخته ایم ، بیایید یک برنامه جستجوی کتاب بسازیم که به کاربر اجازه می دهد نام نویسنده مورد علاقه خود را بگوید و لیستی از کتابها را بدست آورد.
برای شروع ، باید یک قلاب سفارشی دوم ایجاد کنیم که به ما امکان جستجو در API کتابخانه را بدهد. بیایید با ایجاد یک فایل جدید به نام شروع کنیم useBookFetch.js. در این فایل ، ما از همان الگوی زیر پیروی خواهیم کرد useVoice قلاب. ما قلاب های React خود را برای حالت و اثر وارد خواهیم کرد. سپس می توانیم قلاب سفارشی خود را بسازیم:
import { useEffect, useState } from 'react';
const useBookFetch = () => {
const [authorBooks, setAuthorBooks] = useState([]);
const [isFetchingBooks, setIsFetchingBooks] = useState(false);
const fetchBooksByAuthor = author => {
setIsFetchingBooks(true);
fetch(`https://openlibrary.org/search.json?author=${author}`)
.then(res => res.json())
.then(res => {
setAuthorBooks(res.docs.map(book => {
return {
title: book.title
}
}))
setIsFetchingBooks(false);
});
}
return {
authorBooks,
fetchBooksByAuthor,
isFetchingBooks,
};
};
export {
useBookFetch,
}بیایید آنچه را که در این قلاب سفارشی جدید انجام می دهیم ، خراب کنیم. ما ابتدا دو مورد حالت ایجاد می کنیم. authorBooks به طور پیش فرض از یک آرایه خالی استفاده می شود و در نهایت لیست کتاب های نویسنده انتخاب شده را در اختیار شما قرار می دهد. isFetchingBooks پرچمی است که اگر تماس شبکه برای دریافت کتابهای نویسنده در حال انجام است ، به مولفه مصرف کننده ما اطلاع می دهد.
سپس تابعی را اعلام می کنیم که می توانیم با نام نویسنده فراخوانی کنیم ، و با فراخوانی فراخوانی به کتابخانه باز تمام کتابها را برای نویسنده ارائه شده بدست می آوریم. (اگر تازه کار با آن نیستید ، مقدمه SitePoint در Fetch API را بررسی کنید.) در پایان then از واکشی ، ما از طریق هر نتیجه نقشه برداری می کنیم و عنوان کتاب را می گیریم. سپس سرانجام یک شی را با authorBooks ایالت ، پرچم برای نشان دادن اینکه ما در حال گرفتن کتاب ها هستیم ، و fetchBooksByAuthor تابع.
بیایید دوباره به ما برگردیم App.js پرونده را وارد کرده و وارد کنید useBookFetch قلاب به همان روشی که ما وارد کردیم useVoice قلاب. ما می توانیم این قلاب را بنامیم و مقادیر را از بین ببریم و از آنها در م componentلفه خود استفاده کنیم:
const {
authorBooks,
isFetchingBooks,
fetchBooksByAuthor
} = useBookFetch();
useEffect(() => {
if (text !== "") {
fetchBooksByAuthor(text);
}
},
);ما می توانیم از useEffect قلاب برای تماشای text متغیر برای تغییرات. با تغییر متن صوتی کاربر ، این کار به طور خودکار کتابهای نویسنده را واکشی می کند. اگر متن خالی باشد ، ما اقدام به واکشی نمی کنیم. این امر هنگام واکشی غیرضروری هنگام اجرای اولیه م theلفه جلوگیری می کند. آخرین تغییر در App.js م componentلفه افزودن منطق برای ارائه کتابهای نویسنده یا نشان دادن پیام واکشی است:
{
isFetchingBooks ?
'fetching books....' :
<ul>
{
authorBooks.map((book, index) => {
return (
<li key={index}>
<span>
{book.title}
</span>
</li>
);
})
}
</ul>
}آخرین App.js پرونده باید به این شکل باشد:
import React, { useEffect } from "react";
import "./index.css";
import Mic from "./microphone-black-shape.svg";
import { useVoice } from "./useVoice";
import { useBookFetch } from "./useBookFetch";
const App = () => {
const { text, isListening, listen, voiceSupported } = useVoice();
const { authorBooks, isFetchingBooks, fetchBooksByAuthor } = useBookFetch();
useEffect(() => {
if (text !== "") {
fetchBooksByAuthor(text);
}
},
);
if (!voiceSupported) {
return (
<div className="app">
<h1>
Voice recognition is not supported by your browser, please retry with
a supported browser e.g. Chrome
</h1>
</div>
);
}
return (
<>
<div className="app">
<h2>Book Voice Search</h2>
<h3>Click the Mic and say an autors name</h3>
<div>
<img
className={`microphone ${isListening && "isListening"}`}
src={Mic}
alt="microphone"
onClick={listen}
/>
</div>
<p>{text}</p>
{isFetchingBooks ? (
"fetching books...."
) : (
<ul>
{authorBooks.map((book, index) => {
return (
<li key={index}>
<span>{book.title}</span>
</li>
);
})}
</ul>
)}
</div>
<div className="icon-reg">
Icons made by{" "}
<a
href="https://www.flaticon.com/authors/dave-gandy"
title="Dave Gandy"
>
Dave Gandy
</a>{" "}
from{" "}
<a href="https://www.flaticon.com/" title="Flaticon">
www.flaticon.com
</a>
</div>
</>
);
};
export default App;نسخه ی نمایشی
در اینجا یک نسخه آزمایشی از آنچه که ساخته ایم ارائه شده است. سعی کنید نویسنده مورد علاقه خود را جستجو کنید.
نتیجه
این فقط یک نمونه ساده از نحوه استفاده از Web Speech API برای افزودن قابلیتهای اضافی به یک برنامه بود ، اما این امکانات بی پایان هستند. API گزینه های بیشتری دارد که ما در اینجا به آنها نپرداختیم ، مانند ارائه لیست های گرامری ، بنابراین می توانیم ورودی صوتی کاربر را محدود کنیم. این API هنوز آزمایشی است ، اما امیدوارم که در مرورگرهای بیشتری در دسترس باشد تا امکان تعاملات صوتی را برای شما فراهم کند. می توانید مثال کامل در حال اجرا را پیدا کنید CodeSandbox یا در GitHub.
اگر برنامه ای را با جستجوی صوتی ساخته اید و آن را عالی دانسته اید ، به من اطلاع دهید توییتر.




{kind=link}
{kind=link}