
در دهه گذشته ، استفاده از شبکه های عصبی مصنوعی (ANN) به میزان قابل توجهی افزایش یافته است. مردم از ANN ها در استفاده کرده اند تشخیص پزشکی، به قیمت بیت کوین را پیش بینی کنید، و برای ایجاد فیلم های جعلی اوباما! با همه سر و صدا در مورد یادگیری عمیق و شبکه های عصبی مصنوعی ، آیا شما همیشه نمی خواسته اید شبکه ای برای خود بسازید؟ در این آموزش ، ما یک مدل برای شناسایی ارقام دست نویس ایجاد می کنیم.
ما از سخت کتابخانه برای آموزش مدل در این آموزش. Keras یک کتابخانه سطح بالا در پایتون است که روی آن پیچیده شده است TensorFlow، CNTK و تیانو. به طور پیش فرض ، Keras به طور پیش فرض از Backend TensorFlow استفاده می کند و ما برای آموزش مدل خود از همان استفاده می کنیم.
شبکه های عصبی مصنوعی
آن شبکه های عصبی مصنوعی یک مدل ریاضی است که مجموعه ای از ورودی ها را از طریق تعدادی لایه پنهان به مجموعه ای از خروجی ها تبدیل می کند. ANN با لایه های مخفی کار می کند ، که هر یک از آنها یک شکل گذرا است که با یک احتمال همراه است. در یک شبکه عصبی معمولی ، هر گره از یک لایه همه گره های لایه قبلی را به عنوان ورودی می گیرد. یک مدل ممکن است یک یا چند لایه پنهان داشته باشد.
ANN ها یک لایه ورودی دریافت می کنند تا آن را از طریق لایه های پنهان تبدیل کنند. ANN با اختصاص وزنه های تصادفی و تعصبات به هر گره از لایه های پنهان آغاز می شود. همانطور که داده های آموزش به مدل وارد می شود ، با استفاده از خطاهای تولید شده در هر مرحله ، این وزن ها و تعصبات را اصلاح می کند. از این رو ، مدل ما هنگام گذر از داده های آموزش ، الگوی “را یاد می گیرد”.
شبکه های عصبی پیچیده
در این آموزش ، ما می خواهیم رقم ها را شناسایی کنیم – که یک نسخه ساده از طبقه بندی تصویر است. یک تصویر در اصل مجموعه ای از نقاط یا پیکسل است. پیکسل را می توان از طریق رنگهای ملفه آن (RGB) تشخیص داد. بنابراین ، داده های ورودی یک تصویر اساساً یک آرایه 2D از پیکسل ها است که هر یک نشان دهنده یک رنگ است.
اگر بخواهیم یک شبکه عصبی منظم را بر اساس داده های تصویر آموزش دهیم ، باید یک لیست طولانی از ورودی ها ارائه دهیم که هرکدام به لایه پنهان بعدی متصل شوند. این مقیاس بندی روند کار را دشوار می کند.
در یک شبکه عصبی پیچیده (CNN) ، لایه ها در یک آرایه سه بعدی قرار می گیرند (مختصات محور X ، مختصات محور Y و رنگ). در نتیجه ، یک گره از لایه پنهان فقط به یک منطقه کوچک در مجاورت لایه ورودی متصل می شود ، و این فرایند بسیار کارآمدتر از یک شبکه عصبی سنتی است. بنابراین CNN ها هنگام کار با تصاویر و فیلم ها محبوب هستند.
انواع مختلف لایه ها در CNN به شرح زیر است:
- لایه های کانولوشن: این ورودی ها را از طریق فیلترهای خاصی اجرا می کند که ویژگی های تصویر را شناسایی می کند
- لایه های استخر: اینها ویژگی های کانولوشن را ترکیب می کنند و به کاهش ویژگی کمک می کنند
- لایه ها را صاف کنید: اینها یک لایه N بعدی را به یک لایه 1D تبدیل می کنند
- لایه طبقه بندی: لایه نهایی ، که نتیجه نهایی را به ما می گوید
بیایید اکنون داده ها را بررسی کنیم.
مجموعه داده های MNIST را کاوش کنید
همانطور که شاید تاکنون فهمیده باشید برای آموزش هر مدلی به داده های دارای برچسب نیاز داریم. در این آموزش ، ما از مجموعه داده MNIST ارقام دست نویس این مجموعه داده بخشی از بسته Keras است. این شامل یک مجموعه آموزشی متشکل از 60،000 مثال ، و یک مجموعه آزمون 10،000 نمونه ای است. ما داده های مجموعه آموزش را آموزش خواهیم داد و نتایج را بر اساس داده های آزمون اعتبار سنجی خواهیم کرد. علاوه بر این ، ما یک تصویر از خودمان ایجاد خواهیم کرد تا آزمایش کنیم که آیا مدل می تواند به درستی آن را پیش بینی کند.
ابتدا ، اجازه دهید مجموعه داده MNIST را از Keras وارد کنیم. .load_data() روش هر دو مجموعه داده آموزش و آزمایش را برمی گرداند:
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
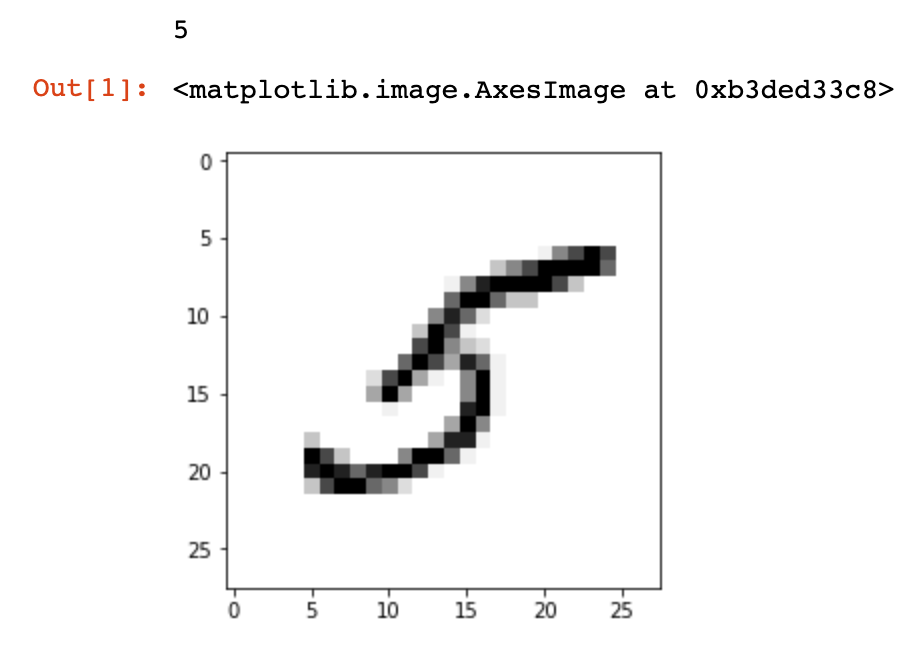
بیایید سعی کنیم ارقام موجود در مجموعه داده را تجسم کنیم. اگر از نوت بوک های Jupyter استفاده می کنید ، برای نمایش نمودارهای درون خطی Matplotlib از عملکرد جادویی زیر استفاده کنید:
%matplotlib inline
بعد ، وارد کنید pyplot ماژول از matplotlib و استفاده از .imshow() روش نمایش تصویر:
import matplotlib.pyplot as plt
image_index = 35
print(y_train[image_index])
plt.imshow(x_train[image_index], cmap='Greys')
plt.show()
برچسب تصویر چاپ شده و سپس تصویر نمایش داده می شود.
بیایید اندازه مجموعه داده های آموزش و آزمایش را بررسی کنیم:
print(x_train.shape)
print(x_test.shape)
توجه داشته باشید که هر تصویر دارای ابعاد 28 x 28 است:
(60000, 28, 28)
(10000, 28, 28)
در مرحله بعدی ، ممکن است بخواهیم متغیر وابسته ذخیره شده در را بررسی کنیم y_train. بیایید همه برچسب ها را تا رقمی که در بالا مشاهده کردیم چاپ کنیم:
print(y_train[:image_index + 1])
[5 0 4 1 9 2 1 3 1 4 3 5 3 6 1 7 2 8 6 9 4 0 9 1 1 2 4 3 2 7 3 8 6 9 0 5]
پاک کردن داده ها
حالا که ساختار داده ها را دیدیم ، بیایید قبل از ایجاد مدل ، روی آنها بیشتر کار کنیم.
برای کار با Keras API ، باید هر تصویر را به شکل (M x N x 1). ما از .reshape() روش انجام این عمل در آخر ، داده های تصویر را با تقسیم هر مقدار پیکسل بر 255 نرمال کنید (از آنجا که مقادیر RGB می توانند از 0 تا 255 باشند):
img_rows, img_cols = 28, 28
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
x_train /= 255
x_test /= 255
بعد ، باید متغیر وابسته را به صورت عدد صحیح به یک ماتریس کلاس باینری تبدیل کنیم. این می تواند توسط to_categorical() تابع:
from keras.utils import to_categorical
num_classes = 10
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
ما اکنون آماده ایجاد مدل و آموزش آن هستیم!
یک مدل طراحی کنید
روند طراحی مدل پیچیده ترین فاکتور است که تأثیر مستقیمی بر عملکرد مدل دارد. برای این آموزش ، ما استفاده خواهیم کرد این طرح از مستندات Keras است.
برای ایجاد مدل ، ابتدا یک مدل متوالی را مقدار دهی می کنیم. این یک شی مدل خالی ایجاد می کند. اولین قدم اضافه کردن یک لایه کانولوشن است که تصویر ورودی را می گیرد:
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=(img_rows, img_cols, 1)))
آ از سرگیری فعال سازی مخفف “واحدهای خطی اصلاح شده” است که حداکثر مقدار یا صفر را می گیرد. بعد ، یک لایه کانولوشن دیگر اضافه می کنیم ، و بعد یک لایه جمع می شود:
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
بعد ، یک لایه “dropout” اضافه می کنیم. در حالی که شبکه های عصبی روی مجموعه داده های عظیمی آموزش دیده اند ، ممکن است مشکلی در نصب بیش از حد وجود داشته باشد. برای جلوگیری از این مسئله ، ما به طور تصادفی واحدها و اتصالات آنها را در طول فرایند آموزش رها می کنیم. در این حالت ، ما 25٪ از واحدها را کاهش خواهیم داد:
model.add(Dropout(0.25))
بعد ، یک لایه مسطح اضافه می کنیم تا لایه پنهان قبلی را به یک آرایه 1D تبدیل کنیم:
model.add(Flatten())
هنگامی که داده ها را در یک آرایه 1D مسطح کردیم ، می توانیم یک لایه مخفی متراکم اضافه کنیم ، که این برای یک شبکه عصبی سنتی طبیعی است. بعد ، قبل از اضافه کردن یک لایه متراکم نهایی که داده ها را طبقه بندی می کند ، یک لایه ترک تحصیل دیگر اضافه کنید:
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
سافت مکس وقتی می خواهیم داده ها را در چندین کلاس از پیش تعیین شده طبقه بندی کنیم ، از فعال سازی استفاده می شود.
تدوین و آموزش مدل
در روند طراحی مدل ، ما یک مدل خالی و بدون عملکرد هدف ایجاد کرده ایم. برای ارزیابی عملکرد مدل باید مدل را کامپایل کنیم و یک تابع از دست دادن ، یک تابع بهینه ساز و یک معیار را مشخص کنیم.
ما باید از a استفاده کنیم sparse_categorical_crossentropy() تابع از دست دادن در صورتی که یک متغیر وابسته به عدد صحیح داشته باشیم. برای یک متغیر وابسته بردار مانند آرایه ده اندازه به عنوان خروجی هر مورد آزمایشی ، استفاده کنید categorical_crossentropy. در این مثال ، ما از adam بهینه ساز. معیار مبنای ارزیابی عملکرد مدل ما قرار دارد ، اگرچه قضاوت فقط برای ماست و در مرحله آموزش استفاده نمی شود:
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
اکنون آماده آموزش مدل با استفاده از .fit() روش. هنگام آموزش مدل باید یک دوره و اندازه دسته مشخص کنیم. دوران یک پاس رو به جلو و یک پاس رو به عقب از همه نمونه های آموزشی است. اندازه دسته ای تعداد نمونه های آموزش در یک پاس به جلو یا عقب است.
سرانجام ، پس از اتمام آموزش ، مدل را ذخیره کنید تا از نتایج آن در مرحله بعد استفاده کنید:
batch_size = 128
epochs = 10
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
model.save("test_model.h5")
وقتی کد بالا را اجرا می کنیم ، همانطور که مدل اجرا می شود ، خروجی زیر نشان داده می شود. در یک دفترچه یادداشت Jupyter در Macbook Air 2018 حدود ده دقیقه طول می کشد:
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
60000/60000 [==============================] - 144s 2ms/step - loss: 0.2827 - acc: 0.9131 - val_loss: 0.0612 - val_acc: 0.9809
Epoch 2/10
60000/60000 [==============================] - 206s 3ms/step - loss: 0.0922 - acc: 0.9720 - val_loss: 0.0427 - val_acc: 0.9857
...
Epoch 9/10
60000/60000 [==============================] - 142s 2ms/step - loss: 0.0329 - acc: 0.9895 - val_loss: 0.0276 - val_acc: 0.9919
Epoch 10/10
60000/60000 [==============================] - 141s 2ms/step - loss: 0.0301 - acc: 0.9901 - val_loss: 0.0261 - val_acc: 0.9919
Test loss: 0.026140549496188395
Test accuracy: 0.9919
در پایان دوره آخر ، دقت مجموعه داده آزمون 99.19 99 است. اظهارنظر در مورد میزان دقت بالا دشوار است. برای اجرای آزمایشی ، دقت بیش از 99٪ بسیار خوب است. با این حال ، با تعدیل پارامترهای مدل ، زمینه های زیادی برای بهبود وجود دارد. وجود دارد ارسال از یک مسابقه شناسایی رقمی در کاگل که به دقت 99.7٪ رسیده است.
آزمون با ارقام دست نویس
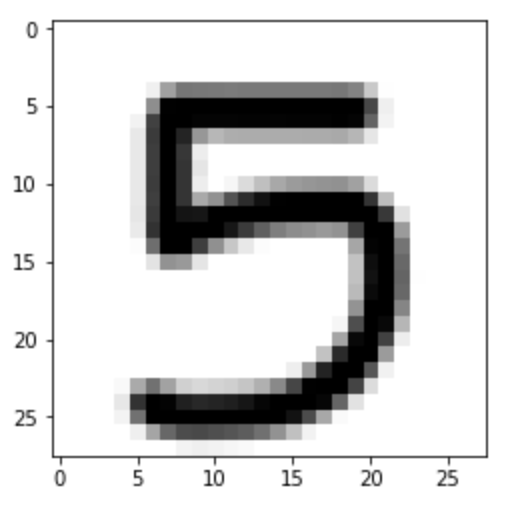
اکنون که مدل آماده است ، بیایید از یک تصویر سفارشی برای ارزیابی عملکرد مدل استفاده کنیم. من میزبانم 28 custom 28 رقمی سفارشی در Imgur. ابتدا ، اجازه دهید تصویر را با استفاده از بخوانیم imageio کتابخانه و کاوش در نحوه مشاهده داده های ورودی:
import imageio
import numpy as np
from matplotlib import pyplot as plt
im = imageio.imread("https://i.imgur.com/a3Rql9C.png")
بعد ، تبدیل کنید مقادیر RGB برای مقیاس خاکستری تعیین می شود. سپس می توانیم از .imshow() روش نمایش داده شده در بالا برای نمایش تصویر:
gray = np.dot(im[...,:3], [0.299, 0.587, 0.114])
plt.imshow(gray, cmap = plt.get_cmap('gray'))
plt.show()
بعد ، تصویر را دوباره شکل دهید و مقادیر را عادی کنید تا در مدل مورد استفاده ما آماده استفاده شود:
gray = gray.reshape(1, img_rows, img_cols, 1)
gray /= 255
با استفاده از مدل از فایل ذخیره شده بارگیری کنید load_model() تابع و پیش بینی رقم با استفاده از .predict() روش:
from keras.models import load_model
model = load_model("test_model.h5")
prediction = model.predict(gray)
print(prediction.argmax())
مدل به درستی رقم نشان داده شده در تصویر را پیش بینی می کند:
5
افکار نهایی
در این آموزش ، ما یک شبکه عصبی با Keras با استفاده از TensorFlow back end برای طبقه بندی ارقام دست نویس ایجاد کردیم. اگرچه ما به دقت 99٪ رسیدیم ، هنوز فرصتهایی برای بهبود وجود دارد. ما همچنین نحوه طبقه بندی ارقام سفارشی دست نویس را که جز a مجموعه داده های آزمون نبودند ، فرا گرفتیم. با این حال ، این آموزش سطح زمینه شبکه های عصبی مصنوعی را خراشیده است. استفاده های بی پایان از شبکه های عصبی وجود دارد که فقط توسط تخیل ما محدود می شود.
آیا شما می توانید دقت مدل را بهبود ببخشید؟ فکر می کنید از چه تکنیک های دیگری استفاده کنید؟ خبرم کن در توییتر.




{kind=link}